Getting started With Pandas
Getting started with Pandas
Pandas adalah perpustakaan (library) sumber terbuka untuk bahasa pemrograman Python yang menyediakan struktur data dan alat analisis data yang efisien. Nama "Pandas" berasal dari "Panel Data" yang merupakan istilah dalam ekonomi dan statistik yang mengacu pada data multidimensional yang diorganisir dalam bentuk tabel. Perpustakaan ini dikembangkan oleh Wes McKinney dan pertama kali dirilis pada tahun 2008.
Beberapa fitur utama dan konsep Pandas meliputi:
DataFrame:
- Struktur data utama di Pandas disebut DataFrame. Ini adalah struktur data dua dimensi mirip tabel database, yang terdiri dari baris dan kolom.
- Setiap kolom dalam DataFrame dapat memiliki tipe data yang berbeda (seperti string, numerik, datetime, dll.).
Series:
- Series adalah struktur data satu dimensi di Pandas. Setiap kolom dalam DataFrame sebenarnya adalah objek Series.
- Seri mirip dengan array atau daftar dalam Python, tetapi memiliki label indeks yang membedakannya.
Fungsi untuk Membaca dan Menulis Data:
- Pandas menyediakan fungsi untuk membaca data dari berbagai format file, termasuk CSV, Excel, SQL, dan banyak lainnya. Fungsi umum termasuk
read_csv(),read_excel(), danread_sql().
- Pandas menyediakan fungsi untuk membaca data dari berbagai format file, termasuk CSV, Excel, SQL, dan banyak lainnya. Fungsi umum termasuk
Pemrosesan dan Manipulasi Data:
- Pandas menyediakan berbagai fungsi dan metode untuk melakukan manipulasi data, seperti penggabungan (merge), penyortiran, filter, dan transformasi data.
- Operasi vektorisasi di Pandas memungkinkan manipulasi data yang efisien dan cepat.
Pengindeksan dan Seleksi Data:
- Pandas menyediakan cara fleksibel untuk mengakses dan memanipulasi data menggunakan indeks atau label kolom.
- Fungsi-fungsi seperti
loc[]daniloc[]digunakan untuk pemilihan berbasis label atau indeks.
Fungsionalitas Statistik dan Analisis:
- Pandas menyediakan berbagai fungsi statistik deskriptif dan analisis data, seperti penghitungan mean, median, korelasi, dan lainnya.
- Metode
groupby()memungkinkan pengelompokan data berdasarkan kriteria tertentu.
Visualisasi Data:
- Meskipun bukan perpustakaan visualisasi utama, Pandas dapat berintegrasi dengan perpustakaan visualisasi seperti Matplotlib dan Seaborn untuk mempermudah pembuatan grafik dan visualisasi data.
Pandas sangat penting dalam analisis data dan ilmu data di Python dan sering digunakan bersama dengan perpustakaan lain seperti NumPy, Matplotlib, dan scikit-learn. Perpustakaan ini mendukung banyak fungsi dan operasi yang memudahkan pekerjaan dengan data tabular, membuatnya menjadi alat yang sangat populer di dunia ilmu data dan analisis data menggunakan Python.
Pandas read csv
Menggunakan fungsi pd.read_csv('nama_file.csv') untuk membaca data dari file CSV ke dalam DataFrame.

Exploring The DataFrame
- Melihat beberapa baris pertama data: df.head().
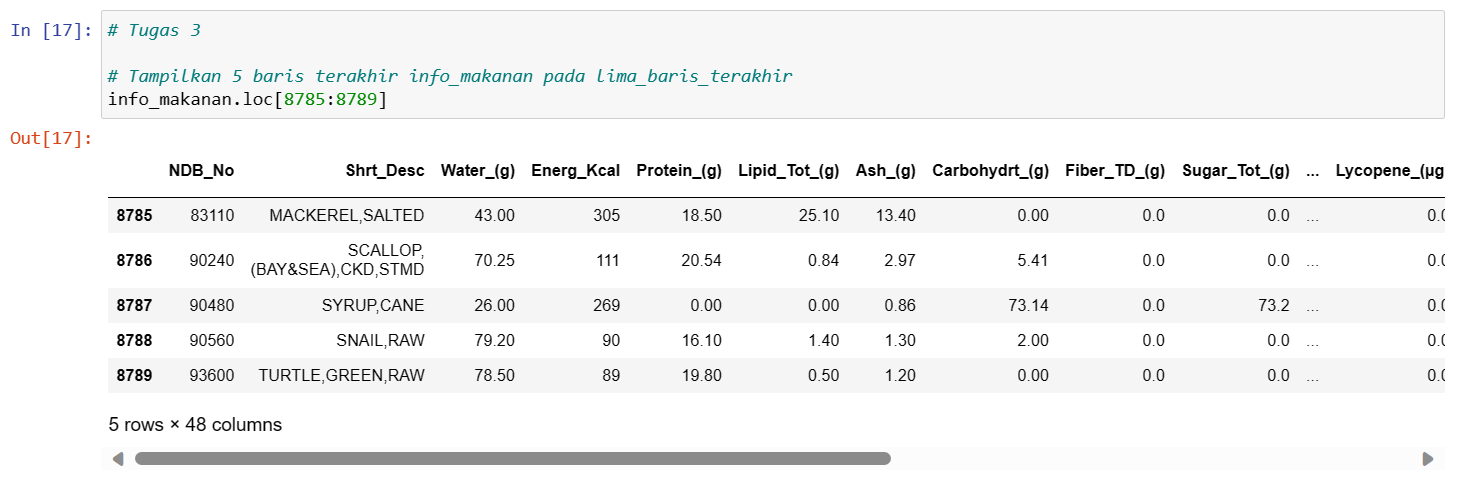
- Melihat beberapa baris terakhir data: df.tail().
- Menampilkan informasi tentang DataFrame: df.info().
- Melihat statistik deskriptif: df.describe().


Series and selecting row
- Mengakses kolom sebagai Series: df['nama_kolom'].
- Memilih baris berdasarkan indeks: df.loc[indeks].

Data Types
- Melihat tipe data kolom: df.dtypes.
- Mengganti tipe data kolom: df['nama_kolom'] = df['nama_kolom'].astype('tipe_data_baru').

Selecting multiple rows
- Memilih beberapa baris berdasarkan indeks: df.loc[indeks_mulai:indeks_akhir].
Selecting Individual Columns
- Memilih satu kolom: df['nama_kolom'].
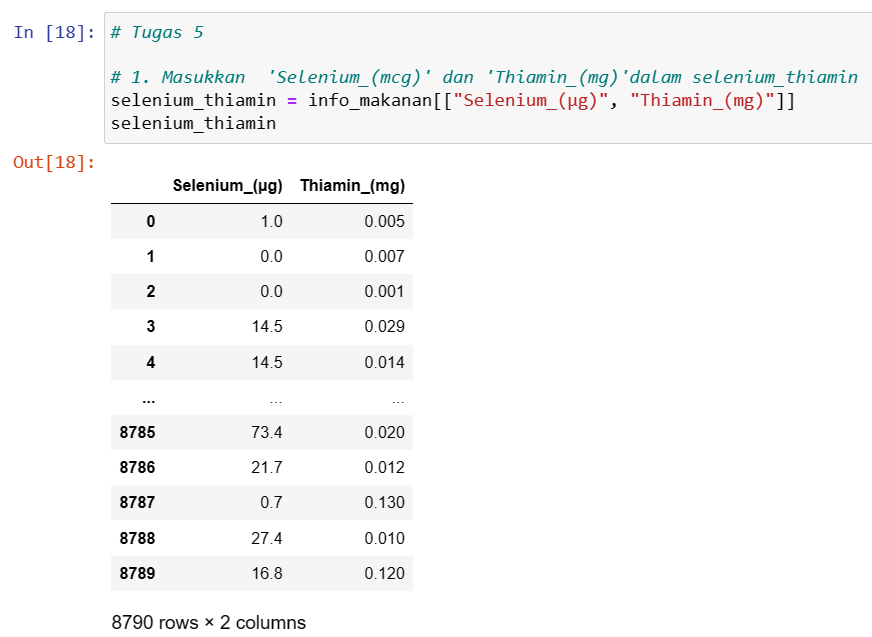
- Memilih beberapa kolom: df[['kolom1', 'kolom2']].

Selecting multiple columns by name
- Memilih beberapa kolom berdasarkan nama: df.loc[:, ['kolom1', 'kolom2']].